Automatic tagging using Azure Computer Vision image recognition
This feature is only available in Color Factory Enterprise
Azure Computer Vision is a cloud service by Microsoft that uses machine learning (AI) to identify objects, faces, and other artifacts in pictures.
Note: Fotoware does not use or develop Facial Recognition technology, and does not support the use of integrations for facial recognition purposes, in any Fotoware solutions, products, or services. Accordingly, the facial recognition option of the Computer Vision service is not available in Fotoware.
Color Factory then stores this information in metadata so that users can search for the information and find relevant content.
What types of information can the Computer Vision service recognize?
- Tags and Keywords
- The accent and dominant color of images (Foreground/Background color, dominant colors, whether a picture is B&W)
- Description - A description of an entire image in human-readable language, using complete sentences, for example, A grey dog running on a beach)
- Celebrities - Celebrities' names are stored in the set metadata field
- Landmarks - Big Ben, the Eiffel Tower, and so on
- Objects - Detects objects in images and stores their coordinates within the picture
- Brands - Detects known brands by their logo (currently only English language supported)
- Adult content - Detects if images are likely to contain adult content.
For each vision type, additional settings let you control the precise information you want to record in the metadata.
Subscribing to Azure Computer Vision
Before using this feature, you need a valid subscription to the Azure Computer Vision service. For more information, see Subscribing to Computer Vision on the Azure portal.
How to configure automatic tagging
Select Azure Computer Vision button to open the configuration screen for this feature.
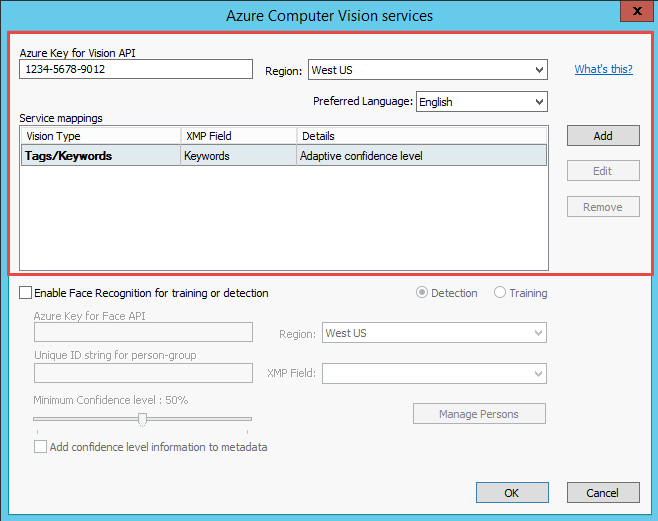
The Azure Vision service that powers the image recognition requires a license. Enter the Vision API key based on the license information you have received.
Next, choose a region; this is the data center that powers the image recognition service. Different regions may offer slightly different image recognition services.
Adding types of information to recognize
Select Add to add a Vision Type to recognize. The example below shows the configuration of tags/keywords, where the service will try to extract keywords based on what it finds in the pictures processed in the channel.
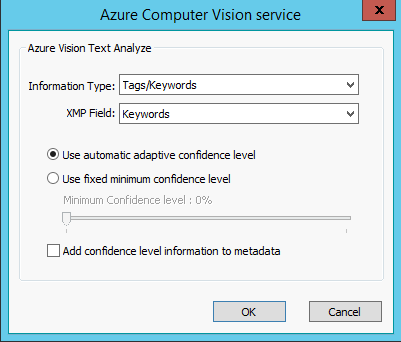
The tags identified by the service are stored in the XMP field you set below.
Confidence level
The automatic confidence level works as follows:
- If the image recognition returns three or fewer tags, all tags are added.
- If fewer than 10 tags are returned, tags with a confidence level of 40% or more are added to the picture.
- If more than 10 tags are returned, tags with a confidence level of 60% are added to the picture.
The confidence level can be set to automatic, or you can manually set a fixed minimum confidence level by dragging the slider to set the level of confidence with which a keyword must be established to be added to the image. There is also the option to add the confidence level to the metadata.